
Non esiste un modo perfetto per organizzare il materiale sul tuo sito web, che si tratti di voci di blog, pagine di dettagli del prodotto, pagine di elenco dei prodotti o persino fotografie.
Tuttavia, le pagine e i tag delle categorie SEO sono un’opzione fornita dalla maggior parte dei sistemi di gestione dei contenuti (CMS come WordPress o joomla).
Puoi sviluppare un’utile struttura organizzativa con l’uso di siti di categorie ampie (ad esempio, scarpe uomo, Magliette,ecc…) e pagine di tag più specializzate (ad esempio, colore, taglia, ecc…). Anche se sono utili, avere troppe pagine di categorie e tag potrebbe essere problematico.
Più precisamente, potrebbero influenzare l’efficienza dell’ottimizzazione dei motori di ricerca (SEO).
Quali problemi sono causati da categorie e pagine di tag non necessarie?
Le due principali aree di preoccupazione relative alle categorie e agli stili di tag dei siti e ai loro effetti sulle prestazioni SEO sono:
- Classifiche in conflitto
- Problemi con il sofraffollamento dell’indice
- Profondità di scansione
Per quanto riguarda la prima categoria, i siti di categorie e tag irrilevanti potrebbero rubare materiale rilevante dal tuo sito web a causa di conflitti di posizionamento.
Ciò implica che le pagine interne del tuo sito competono per gli stessi visitatori (cannibalizzazione).
Devi prima comprendere cos’è un bot di scansione dei motori di ricerca e come funziona prima di poter affrontare la seconda categoria, i problemi di sovraffollamento della scansione/indicizzazione.
Un software che esegue la scansione di Internet per tenere traccia degli URL attivi è noto come bot di scansione dei motori di ricerca, noto anche come crawler o web spider.
Queste pagine vengono sottoposte a scansione e quindi indicizzate dai motori di ricerca. Di conseguenza, potrebbero apparire nei risultati di ricerca.
Il numero di pagine attualmente attive su Internet cambia spesso. Quindi, come fanno i crawler a decidere quali pagine esplorare?
Le mappe dei siti, o un elenco di URL di siti Web, vengono utilizzate dai crawler nel file sitemap.xml di un sito Web:

Una volta avviata la scansione, potrebbe anche imbattersi in più URL utilizzando i collegamenti interni sui siti che ha già scansionato.
Inoltre, alcune pagine verranno sottoposte a scansione.
I robot di scansione, tuttavia, non sono in grado di eseguire la scansione di ogni pagina di un sito web.
Di conseguenza, eseguono la scansione delle pagine che sembrano essere i più cruciali.
Per i siti Web che contengono molte pagine inutili, ad esempio pagine di categorie e tag, questo potrebbe rappresentare un problema.
Potrebbero provocare un “scansione eccessiva", ovvero quando il bot di scansione esegue la scansione di pagine inutili.
Ciò ha un effetto dannoso sul margine massimo di scansione del sito Web, che alla fine si traduce nella perdita di pagine veramente pertinenti.
Citiamo un esempio: un cliente stava ricevendo traffico verso uno dei suoi siti /tag/.
Anche se questo non è sempre una cosa negativa, per questo cliente lo è stato.
Perché? L’URL della pagina /tag/ e la pagina di di prodotto primario erano abbastanza simili.
Ciò ha portato a una certa cannibalizzazione interna e a una grande incertezza per i visitatori del sito web.
Come abbiamo risolto?
Siamo stati in grado di determinare in che modo l’eliminazione di pagine di categorie e tag inutili ha aumentato il traffico verso le pagineche desideravamo che i clienti visitassero utilizzando Google Search Console.
Diamo un’occhiata.
Quali effetti hanno avuto le pagine noindexing?
Abbiamo prima analizzato gli ingressi sulle pagine in questione ed evidenziato la problematica di contenuto simile cannibalizzato.
Queste pagine simili confondevano sia il robot di google che i clienti, che atterravano in sostanza in una pagina di poco interesse economico per il cliente, rilevando notevoli “bounce" (uscite rapide dalla pagina da parte del visitatore che a tutti gli effetti non voleva vedere quella pagina).
La soluzione di imporre il “noindex" sulla pagina tag ha di fatto eliminato dall’indice la pagina che cannibalizzava il prodotto.
Google Search Console ha segnalato che in seguito all’aggiornamento si è verificata un’improvvisa diminuzione degli accessi alla pagina dei tag e un aumento dei clic alla pagina del prodotto.
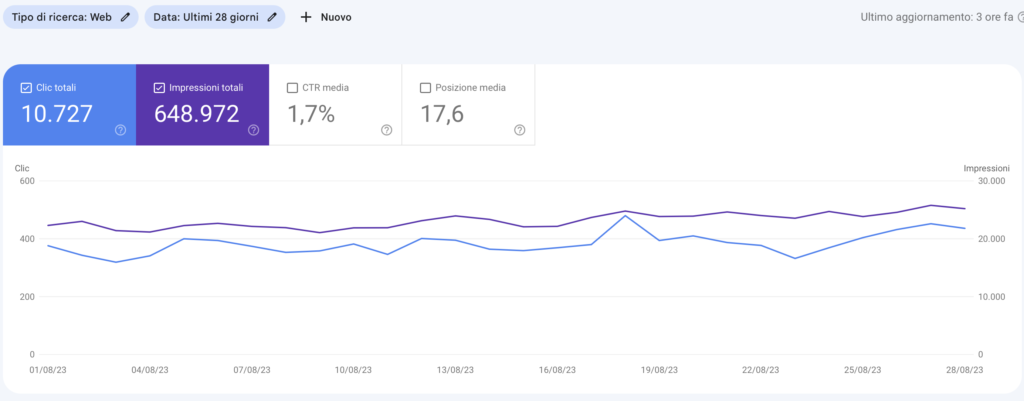
Google ha smesso di fornire questo materiale cannibalizzante che veniva visualizzato per gli stessi termini di ricerca della pagina di accesso principale aggiungendo un tag noindex alla pagina.
Ciò ha ridotto l’ambiguità sia per Google che per gli utenti.
Inoltre, questo ha ridotto il volume della scansione e ha separato gli URL che volevamo indicizzare da quelli non importanti o addirittura dannosi, come quello sopra.
Anche se questa tattica non è sempre consigliata, in questo caso particolare il cliente ne ha tratto beneficio.
Questo è un tipico caso in cui la frase SEO “dipende" è veramente vera.
Quando dovrebbero essere indicizzate o non indicizzate le pagine?
Le pagine Noindexing sono in gran parte una strategia SEO “dipende", come già detto.
Di conseguenza, come decidi se indicizzare o noindex le pagine del tuo sito web?
L’utente dovrebbe trovare valore nelle pagine indicizzate. Desideri che i motori di ricerca elenchino questi siti in modo che gli utenti possano individuarli.Quando esiste la possibilità di cannibalizzazione, una pagina del tuo sito web non dovrebbe essere indicizzata.
Ciò indica che il contenuto o l’URL della pagina è talmente simile a una delle pagine prioritarie del tuo sito web da dirottare i visitatori dalla pagina prioritaria.
Anche una pagina che non vuoi rendere pubblica può essere noindex.
Ad esempio, una pagina di iscrizione ad un servizio per non renderla obiettivo di SPAM robot.
Anche le aree di staging e i siti protetti da password dovrebbero essere deindicizzati.
Domande e risposte
Cosa significa tagging del sito web?
I tag del sito web sono parole o frasi utilizzate per classificare il materiale. Un esempio di tag di marketing potrebbe trovarsi in un articolo di blog sul marketing digitale. Pertanto, il tagging su un sito web è uno sforzo per mettere insieme materiale simile per semplificare la ricerca.
Cosa distingue le categorie e i tag l’uno dall’altro?
Argomenti ampi chiamati categorie vengono utilizzati per organizzare il materiale sui siti web. Se gestisci un blog di abbigliamento, ad esempio, potresti avere sezioni per “magliette", “pantaloni", “scarpe", ecc. A ogni elemento del materiale possono essere assegnati numerosi tag, che sono designazioni più descrittive.
L’equivalente sarebbe taggare una maglietta verde con le parole “t-shirt", “verde", “abbigliamento uomo" ecc. per continuare l’esempio del blog di abbigliamento.
Cosa differenzia il noindex dal nofollow?
Un tag noindex indica ai crawler di non indicizzare l’URL quando viene introdotto in una pagina web. Di conseguenza, la pagina non viene visualizzata nei risultati dei motori di ricerca. Un tag nofollow indica ai crawler di non eseguire la scansione degli URL collegati da una pagina dicendo loro di non farlo. Un sito Web potrebbe essere contrassegnato come nofollow, noindex o anche entrambi contemporaneamente.
Conclusione
Categorie e tag potrebbero essere i tuoi migliori amici quando si tratta di organizzare il materiale sul tuo sito web. Tuttavia, dovresti fare attenzione a non indicizzare troppi siti di categorie e tag.
In questa situazione è possibile utilizzare il tag noindex.
Il noindex dei siti di categorie e tag non necessari elimina la possibilità di cannibalizzazione dei contenuti e riduce il volume di scansione. Ciò va a vantaggio sia della funzionalità del tuo sito web che dei visitatori del sito web che altrimenti potrebbero essere fuorviati dalla ripetizione dei contenuti.
Hai dubbi sui vantaggi e sugli svantaggi di non indicizzare determinate pagine del tuo sito web?